
The increase in data has led to a growing need for graph databases or technologies. With a graph database, the relationships that exist within the data can be stored, refined and queried properly. A graph database, therefore, is a database created to store data without restricting it to a pre-set model. The data in these graph-based technology expresses how each entity is related to others. Nodes and edges are quite important when looking at graph databases as the later represents the relationship with the former. This nodes and edges setup, makes the retrieval and querying of relationships easier. Retrieving complex hierarchical structures is an advantage that these graph technologies have over relational databases. The software review forum G2 has a list of the top-rated graph databases in the market. The leading graph database technologies on G2 have had more reviews, a higher percentage of positive feedback, more data generated from other online networks and social platforms.
Continue readingIntroduction to a graph data structure in Python
Graphs play an important part in intelligent technologies such as recommendation engines, search engines, fraud detection applications, network mapping, customer journey applications, latency evaluation and dependency management. Graphs data structures are also powerful in social networks such as Twitter, Facebook, LinkedIn and a few others. Graphs in the context of the social graph are used to recommend friends, events, company pages, jobs and personalise the ad experience. These are some of the use cases of graph data structures and applications.
A quick reminder of the definition, graphs are considered to be the composition of vertices (nodes) with respective pairs of edges(also known as links or arcs). In a nutshell, they are viewed to comprise a determined set of nodes and edges which connect these given nodes.
The example below adapted from GeekforGeeks indicates 5 nodes {0,1,2,3,4} and 7 edges {01,12,23,34,04,31,13,14}
Continue readingDifferent ways of representing Graphs
Graph data can be represented in different formats for onward computation. The choice of the graph representation hugely relies on the density of the graph, space required, speed and weight of edges. The main ways a graph can be represented are as an adjacency matrix, incidence matrix, adjacency list and incidence list.
Adjacency Matrix: This is one of the most popular ways a graph is represented. One of the core aims of this matrix is to assess if the pairs of vertices in a given graph are adjacent or not. In an adjacency matrix, row and columns represent vertices. The row sum equals the degree of the vertex that the row represents. It is advisable to use the adjacency matrix for weighted edges. You replace the standard ‘1’ with the respective weight. It is easier to represent directed graphs with edge weights through an adjacency matrix. Adjacency matrix works best with dense graphs. As dense graphs usually have twice the size of the edges to the given nodes.
Continue readingThe rise of eight different types of graphs
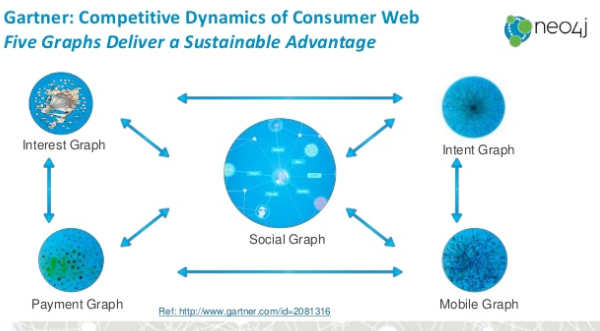
We are witnessing the rise and adoption of graph databases across different verticals. Gartner acknowledged the five different types of graphs as social, intent, consumption, mobile and interest. In a presentation titled: Graph All the things! Introduction to graph databases, the team from Neo4j captured Gartner’s graph classifications in the illustration below. There is a slight difference in how one of the types of a graph is named by Neo4j in comparison to Gartner. To Neo4j it is a payment graph while to Gartner it is the consumption graph. There is the argument that a consumption graph is a better name as we do not necessarily pay for every consumption. We will now look at each graph and add some additional types.
An introduction to comparable entity mining at a structural level
The comparing of entities is usually important in human decision making.
We are constantly comparing entities daily from holiday destinations, new mobile phone and next family car. Comparing entities look at the relatedness of these objects or concepts. Relatedness does not look at only similarity (analogy) but other relational structures such as resistance (antithesis), discrepancy (anomaly) and incompatibility (antinomy).
Comparative entity mining is crucial to any keyword, concept, content, product and marketing strategy. This is because no product exists in isolation. It is therefore important for businesses to place themselves in the shoes of potential customers and explore the alternative products that are vying for the same attention and mind space. Conducting this exercise will help brands position their products in a more compellingly through through engaging branding and compelling storytelling.
The field of biomedical informatics have employed comparative entity mining between genes and proteins. These comparisons have now extended to diseases. The comparisons in the biomedical field looks at functional similarities more than sequential similarities. This has inspired me to classify comparative entity mining to three stages: structural, functional and sequential.
This blog will focus on the structural stage of comparing entities. We will be comparing bananas to plantains. When looking at an entity or a concept from the structural level we focus more on the size, colour, shape and physical properties. The internal properties that make up the product.
Continue readingThe importance of fine grained named entity recognition
Name entity recognition is usually viewed as a low level NLP task but could be crucial to other tasks such as named entity disambiguation and linking. It is also relevant for information retrieval and question and answering applications. Standard named entity recognition classes are usually person, location and miscellaneous. I used the AllenNLP demo application to run a quick NER test for the Hacksaw ridge storyline. The text was extracted from the IMDB website and the below image indicates the entities. Previous research led to the identification of three core classes – person, location and organisation. During the Computational Natural Language Learning conference of 2003, a miscellaneous type was then added to the mix
The below reveals the four main entity classes or the non-fine grained, All four (person, organisation, location and miscellaneous) entity tags are highlighted. Desmond T. Doss is the name of the star character in the story and it is accurately identifies him as a person. When his surname was mentioned (Doss’s), it also has the accurate personal tag. The miscellaneous tag was used for events like the ‘Battle of Okinawa’ and a thing ‘Congressional medal of honor.’
Whilst the stas Further research also introduced geopolitical entities such as weapons vehicles and facilities. These were all contained in the article, “An empirical study on fine-grained named entity recognition”, and the authors further revealed that the apparent challenges of developing a fine-grained entity recognizer are because of the selection of the tag set, creation of training data and the creation of a fast and accurate multi-class labelling algorithm.
Continue readingA Count-based and Predictive vector models in the Semantic Age
Computer applications such as search engines and dialogue systems usually process a large volume of text on a regular basis. These systems have progressed over the years due to advanced word embeddings, progressive research and modern machine learning libraries. It is believed that audio and visual datasets have dense high-dimensional datasets encoded as vectors of a separate raw pixel. Text generated from natural language is usually understood to contain vectors that are sparse when compared to video and visuals.
Vector space models (VSM) embed or represent words in a continuous vector space. In this respect, words that are semantically similar are plotted to nearby points. As representing words as unique and distinct ids can usually lead to a sparsity of data. Going this route will require a large amount of data to be collected to effectively train statistical models. This is why vector representation of words is useful to address the problem of sparsity and enhance semantic interpretation. I ran a search for romantic dinner on Google and one of the people also ask questions was ‘Where can I eat for anniversary?’ We can clearly see the semantic similarity of the term ‘romantic’ and ‘anniversary’ used within the context of food or dining. You would normally expect a distance between the vector representation of these words but from a contextual perspective, an anniversary is usually expected to be romantic as it will involve couples celebrating a milestone in their relationship or marriage.
Continue reading